Hibernate
1.Hibernate 持久化类的编写
1.1什么是持久化类
持久化类:指的就是一个java类与数据库表建立了映射关系以后,这个类就称为是持久化类
持久化类=java类+映射文件
1.2持久化类的编写规则
- 对持久化类提供无参数的
构造方法:hibernate需要反射来创建持久化类的实例。(new instance 就能创建了) - 对持久化类的属性私有化,对私有属性提供共有的
get/set方法: - 在持久化类中提供一个
oid与表中的主键映射 - 编写的时候,属性最好使用包装类
- 持久化类尽量不要使用fianl修饰(延迟加载时,需要产生代理对象,这个代理对象使用javassist技术实现,就是产生一个子类对象,所以不能用final)
2.Hibernate的主键生成策略
2.1区分自然主键和代理主键
- 自然主键:自然主键指定是建表的时候使用对象中本身属性作为表的主键。创建一个人员表,人会有身份证号,身份证号是唯一不可重复的,现在使用了身份证作为主键的话,属于自然主键。
代理主键:代理主键指的是没有使用对象中的自身的属性作为表的主键,使用与对象不相关的属性作为表的主键。创建一个人员表,人会有身份证号,没有使用身份证号,在建表的时候使用id字段作为表的主键。
建表的时候建议使用代理主键,自然主键有可能会参与到业务逻辑中。有可能出现重复或者有的时候可能需要修改,这个时候主键不能修改的,所以说自然主键不能使用了。
2.2Hibernate主键生成策略
主键不应该由用户自己输入,应该有程序生成。Hibernate框架提供了很多主键生成的方式。
- increment: 自动增长,使用的是Hibernate中提供的自动增长的机制。适用于short,int,long. Hibernated底层使用查询一下表中的主键的最大值,select max(cust_id) from customer;然后将这个值+1作为下一条记录的主键。会有并发访问问题。
- identity: 自动增长,使用的是数据库的自动增长机制。适用于short,int,long,适用于有自动增长机制的数据库(MySQL,SQLServer),Oracle没有自动增长,不能使用identity。
- sequence: 序列,使用的是序列的方式完成数据库的主键的生成。(Oracle,DB2这种数据库可以使用序列)。适用于short,int,long
- native : 本地策略,根据底层数据库不同,自动选择使用identity还是sequence适用于short,int,long
- uuid : 适用于字符串类型的主键,产生随机字符串作为表的主键。
- assigned : Hibernate不管理主键,用户手动设置主键的值。
3.hibernate持久化类的三种状态
hibernate为了更好的管理持久化类,将持久类分为三种状态:
- 瞬时态(Transient):没有唯一标识OID,没有被session管理。
- 持久态(Persister):有唯一标识OID,被session管理。
- 脱管态(Detached):有唯一标识OID,没有被session管理。

3.1 持久态对象特殊能力:
自动更新数据库:
3.2持久化类的三种状态转化
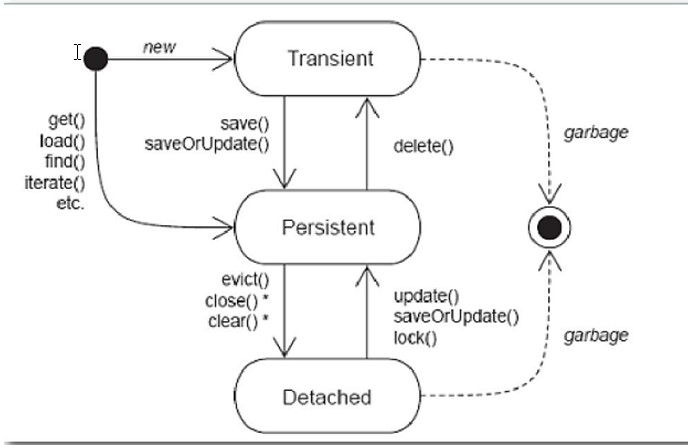
- 瞬时态:
- 获得:
Customer customer=new Customer(); - 状态转化:
- 瞬时—>持久:save,saveOrUpdate
- 瞬时—>脱管:customer.setCust_id(1);
- 获得:
- 持久态:
- 获得:
get/load/find/iterate(都是查询) - 状态转换:
- 持久—>瞬时:delete
- 持久—>脱管:close/clear(清空所有对象)/evict(清空一个对象)
- 获得:
- 脱管态:
- 获得:
Customer customer=new Customer();
customer.setCust_id(1); - 状态转换:
- 脱管—>持久:update/saveOrUpdate
- 脱管—>瞬时:customer.setCust_id(null);
- 获得:
4.Hibernate的一级缓存
4.1什么是缓存
缓存是内存中的一块空间,提升性能存在。将数据源数据存入到内存中,再次获取的时候从缓存中获取,不需要进行查询的操作。
4.2什么是一级缓存
Hibernate的性能相对来说是比较差的,里面提供了很多性能优化手段,其中缓存就是优化的一部分。
Hibernate共分为两个级别的缓存:
一级缓存:称为session级别的缓存。自带的,不可卸载的。- 二级缓存:称为sessionFactory级别的缓存。需要配置的缓存的插件。
一级缓存是由Session中的一系列java集合组成,生命周期贯穿了整个session周期,可以说是一个session级别的缓存。

而且缓存的是对象的地址:(第二遍的时候根本就没查询)
4.3一级缓存的快照区
session有缓存区(sess/persistenceContext/entitiesByKey/table/?/value)跟快照区(sess/persistenceContext/entityEntryContext/head/entity/loadedState)
缓存即使变化,快照区一旦生成就不变化,直到事务结束之后。
当提交事务的时候,比对一级缓存区和快照区的数据是否一致。如果一致,不修改数据库,如果不一致,就会更新数据库。
4.4一级缓存的管理的方法
close
clear:清空所有一级缓存
evict:清空单个缓存对象
5.Hibernate事务的管理
5.1事务的回顾
- 什么是事务:指的是逻辑上的一组操作,组成这组操作的各个单元要么一起成功要么一起失败
- 特性:
- 原子性:事务是不可分割的
- 一致性:事务执行的前后,数据完整性保持一致。
- 隔离性:一个事务的执行不应该受到其他事务的干扰
- 持久性:一旦事务结束,持久到数据库中
- 问题:
- 读问题:
- 脏读:一个事务读到另一个事务未提交的事务。
- 不可重复读:一个事务读到另一个事务已提交的update的数据
- 虚读/幻读:一个事务读到另一个事务已提交的insert的数据
- 写问题:
- 丢失更新(事务提交)
就是在多个更新操作同时运行时,数据库可能丢失前面更新的数据。 - 丢失更新(事务回滚)
- 丢失更新(事务提交)
- 读问题:
- 解决读问题:
- 设置事务的隔离级别:
- 未提交读(read uncommitted):以上情况都有可能发生。
- 已提交读(read committed):避免脏读,但是不可重复读和虚度都有可能发生。
- 可重复读(repeatable read):避免脏读和不可重复读,但是虚度有可能发生。
- 串行化的(serializable):解决所有问题
- 设置事务的隔离级别:
- 解决写问题
- 悲观锁:
在get方法中添加排它锁Customer customer=session.get(Customer.class,1L,LockMode.UPGRADE);
这样在同时运行多个更新操作时,一个运行完了才能运行下一个。 - 乐观锁:
在实体上加一个版本号:Integer version,
在映射文件中配置标签version,名字写上实体中的版本号名字
每次执行操作修改操作的时候,版本号就会自动加一,
如果同时开启两个更新操作,版本号不一致会会报错
- 悲观锁:
5.2hibernate的事务管理
- 设置事务的隔离级别:

- 1—Read uncommitted isolation
- 2—Read committed isolation
- 4—Repeatable read isolation
- 8—Serializable isolation
- 与线程绑定的session的使用:

设置了这个属性后就可以用:
session.getCurrentSession();//表示从当前线程上获取session
而且用这种当时获取的session,不用session.close(),因为线程结束之后会自动关闭。手动关闭会报错。
5.3hibernate事务的其他的api
- Query :HQL查询
HQL(Hibernate Query Language):Hibernate查询语言,语法与SQL类似,面向对象的查询方式。
|
|
- Criteria : QBC查询
QBC(Query By Criteria):条件查询,更加面向对象的方式
|
|
- SQLQuery : SQL查询
|
|


