Oracle 第二阶段
查询
子查询
- 1.查询比雇员7654工资高,同时从事和7788的工作一样的员工
select ename,job,sal from emp where sal>(select sal from emp where empno=7654) and job=(select job from emp where empno=7788) 2.查询每个部门最低工资及最低工资的部门名称和雇员名称
select d.deptno,dname,empno,ename,sal from (select deptno,min(sal) minsal from emp group by deptno) mindept,emp e,dept d where mindept.deptno=e.deptno and mindept.deptno=d.deptno and mindept.minsal=e.sal3.找到员工表中薪水大于本部门平均工资的所有员工
select ename,sal from (select deptno,avg(sal) avgsal from emp group by deptno) s,emp where s.deptno=emp.deptno and emp.sal>s.avgsal- 5.统计每年入职的员工个数
select to_char(hiredate,'yyyy'),count(*) from emp group by to_char(hiredate,'yyyy')
行列转换:
本来是这样的: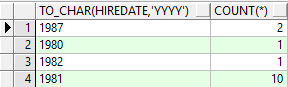
要变成这样: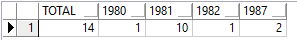
|
|
因为转换之后因为,前面有查询总和已经用了一个聚合函数sum用到了group by的元素,所以后边不能跟普通的字段,必须转成聚合函数,所以加一个sum加avg等其他的聚合函数也行
分页查询
- 0.找到员工表中工资最高的前三名
select rownum ,s.* from (select * from emp order by sal ) s where rownum <= 3有一个虚列叫做rownum,每一个表都有一个虚列,虚表都是按顺序排序从1开始,排序可以让表排序后的表作为一个新表然后再取前几个
1.查询员工表,将员工工资进行降序查询,并进行分页取出第一页,一页三条记录
select rownum ,s.* from (select * from emp order by sal ) s where rownum <= 3- 查询员工表,将员工工资进行降序查询,并进行分页取出第二页,一页三条记录
rownum是只能查询出小于它的大的不能查询出来,rownum>3,就不行了所以用到了嵌套,让rownum成为一个真实的列
select * from (select * from rownum r,e.* from (select * from emp order by sal desc) e) e1 where e1.r>3 and e1.r<6
所以可以提取一个分页公式
|
|
集合运算(了解)
- 1.查询工资大于1200并且job是SALESMAN(intersect)交集
select * from emp where sal>1200 intersect select * from emp where job='SALESMAN' - 2.查询工资大于1200或者job是SALESMAN(union)并集
select * from emp where sal>1200 union select * from emp where job='SALESMAN' - 3.求工资大约1200和job是SALESMAN的差集(minus)差集
select * from emp where sal>1200 minus select * from emp where job='SALESMAN'
DDL(Data Definition Language)语句管理表
/
create tablespace 表空间名称
datafile 数据文件路径
size 100m
autoextend on
next 10m;
/
确定当前用户有dba权限
- 1.创建itcast001表空间
create tablespace itcase001 datafile 'c:/itcast.dbf' size 100m autoextend on next 10m - 2.创建itcastuser用户
create user zc identified by zc default tablespace itcase001 - 3.为itcastuser用户赋予dba权限
grant dba to zc
Oracle数据类型
- 字符类型
char:固定长度类型 varchar2:可变长度类型,可保存1333多个汉字(varchar快被淘汰了) - 数值类型
number(3):999 3位 number(3,2):9.99 3位保留两位小数 - 日期类型
date:mysql中日月年,oracle中精确到时分秒,相当于MySQL中的datetime timestamp:精确到秒的后9位 - 大数据类型
*/long:大数据字符类型,2G Clob:存放字符类型,4G Blob:存放二进制类型,4G
DML创建表
- 0.创建person表,字段为pid,pname
create table person(
pid number(10),
pname varchar2(50)
)
Oracle表中的增删改查
Oracle中的事务需要手动commit提交
Oracle是默认不提交事务的,需要手动提交,不提交的话查也能查到
- 1.为person表新增一条数据
insert into person values(1,'张三'); commit; - 2.修改person表中的一条数据
update person set pname='李四' where pid='1'; commit; - 3.删除person表中的一条数据
delete from person where pid=1;commit;
select * from person fro update;这样可以把表的数据的内容查出来,并且可以修改内容,记得提交事务
修改表列的属性
- 1.给person表增加sex性别列,类型为number(1)
alter table person add sex number(1); - 2.修改person表列sex类型为char(1)
alter table person modify sex char(1); 修改的时候里面不能有值 - 3.修改person表sex列为gender
alter table person rename column sex to gender; - 4.删除person表的gender列
alter table person drop column gender; - 5.删除person表中所有数据
delete from person where 1=1; - 6.摧毁person表(truncate table 表名)
- 直接摧毁表结构后重构表,比delete要很快,但是没法按照条件删除
truncate table person;
- 直接摧毁表结构后重构表,比delete要很快,但是没法按照条件删除
约束
1.创建person表,pid为主键,pname,gender(主键约束primary key)
- primary key方式
create table person( pid number(10) primary key, pname varchar2(50) ) 这样会自动生成一个主键的名称 - constraint 主键名 primary key(字段),方式
create table person( pid number(10), pname varchar2(50), constraint pk_pid primary key(pid) ) 会生成一个给出的主键名
- primary key方式
2.创建person表,pname非空,gender(非空约束not null)
`create table person(pid number(10), pname varchar2(50) not null, constraint pk_pid primary key(pid))`
- 3.创建person表,pid,pname是唯一,(唯一约束unique)
`create table person(
)`pid number(10), pname varchar2(50) unique, constraint pk_pid primary key(pid) - 4.创建person表,pid,gender—检查约束check(列名 in (值)) gender只能为1或2
`create table person(
)`pid number(10), gender number(1) check(gender in (0,1)), constraint pk_pid primary key(pid)
外键约束
/
constraint fk_order_orderid foreign key(外键) references 对应的表(对应的主键)
/
- 1.创建orders表,字段为order_id(主键),total_price
create table orders(
)order_id number(10) primary key, total_price number(5,2) - 2.创建order_detail表,字段为detail_id(主键),order_id(外键),item_name
create table order_detail (
)detail_id number(10) primary key, order_id number(10), item_name varchar2(50) constraint fk_order_id foreign key(order_id) references orders(order_id)
–3.为orders表和order_detail表插入数据
–4.删除orders表和order_detail表中的数据
– 强制删除
drop table orders cascade constraint;
– 级联删除
create table order_detail (
detail_id number(10) primary key,
order_id number(10),
item_name varchar2(50)
constraint fk_order_id foreign key(order_id) references orders(order_id) on delete cascade
)
Oracle事务(了解)
- 设置savepoint 回滚点,再次修改数据后用rollback to 回滚点,回滚数据
|
|
- 不可重复读(Oracle默认Read Committed),幻读(MySQL默认Repeatable Read)
- 脏读(Read Uncommitted)
情景:A事物读取了B事物修改,但未提交的数据
问题:若B回滚了事物,A就读到了错误数据。 - 不可重复读(Read Uncommitted)
情景:A事物查询数据,B修改了数据,A又查询数据
问题:A事物前后两次数据不一样 - 幻读(Repeatable Read)
情景:A事物查询数据,B事物插入数据,A又查询数据
问题:A事物感觉出现了幻觉,多了些数据 - 串行(Serializable):这种隔离级别将事物放在一个队列中,每个事物开始之后,别的事物被挂起。同一个时间点只能有一个事物能操作数据库对象。这种隔离级别对于数据的完整性是最高的,但是同时大大降低了系统的可并发性。
管理其他数据库对象
exists / not exists
select … where exists(查询语句)
exists:当查询结果不为null,返回true
当查询结果为null,返回false
0.例:查询出所有信息
select * from emp where exists (select * from emp where ename="SMITH")
意思是()里面相当于true所以会显示所有的信息1.查询出有员工的部门
select * from dept where exists (select * from emp where dept.deptno=emp.deptno)在这里里面的那条语句不能再加一个
from dept,因为加载的时候要加载外边的那个dept,如果里边加上了就是加载的里边的那个
视图
视图:就是一张虚拟表,本身不存放数据,数据来源于原始表
创建create [or replace] view 视图名 as sql查询语句;
- 1.创建视图
create or replace view view_emp as select empno,ename,job,hirdate from scott.emp; - 2.查询视图
select * from view_emp - 3.修改视图中7369的名字为’smith’
update view_emp set ename='smith' where empno=7369 - 4.删除视图
drop view view_emp; - 5.创建只读视图(关键字 with read only)
create or replace view view_emp as select empno,ename,job,hirdate from scott.emp with read only;
视图就是一个虚表不存数据,修改视图中的数据实际上就是修改表中的数据
在当前用户下创建视图,就能够更改视图,但是如果在别的用户下对当前用户的表来创建视图就不能修改删除了,如果想修改就需要真正的DBA权限去赋予权限了
- 创建视图权限,一般网上找都是说的这句,但光有这句话是不行的
grant create view to itcastuser; - 授予查询权限
grant select any table to itcastuser; - 授予权限
grant select any dictionary to itcastuser;
序列
序列:类似于MySql的自动增长
|
|
- 1.创建序列
create sequence emp_seq; - 2.如何查询序列(currval,nextval)
第一次的时候必须用nextval因为,第一次还没生成,不能取当前值,序列一旦增长就不能回去了select emp_seq.currval from dual 当前的值 select emp_seq.nextval from dual 下一个值 - 3.删除序列
drop sequence emp_seq - 4.为person表插入数据,用序列为id赋值
insert into person values (emp_seq.nextval,'11',1)
commit;
序列跟表没有关系,就是一个数,因为Oracle中没有自动增长机制,所以可以用它做自动增长
索引
目的是提高检索速度
语法:create index 索引名称 on 表名(列名);
原则:
- 大数据表才创建索引,
- 为经常用到的列创建索引,
- 索引的层数不要超过4层,也就是on 表名(列名1,列名2)这里的列名不要超过4个
多列索引:
create index person_index on person(pname,gender)后面可以加,多几个字段
但是这样不好,因为创建索引多了就慢了
- 创建索引
create index person_index on person(pname)
-删除索引drop index person;`
- 创建100万条的数据
|
|
创建数据之后根据pname查询一条数据会有点慢,用了索引就快了
以后面试的时候记住数据库优化有索引这回事
什么时候创建搜索引?
同义词(了解)
为表创建别名
- 同义词和视图的区别:不需要dba权限就可以创建同义词
- 视图可以隐藏列,同义词不可以去掉列只是整张表的复制
- 作用:缩短对象的名称方便访问
- 可以取两个别名,改一个就都变了
- 创建
create public synonym 同义词名 for 目标表名create public synonym sysno_emp for scott.emp; - 删除
drop public synonym 同义词名
- 创建


