什么是hadoop
解决问题
- 海量数据的存储(HDFS)
- 海量数据的分析(MapReduce)
- 资源管理调度(YARN)
作者:Doug Cutting
受Google三篇论文的启发(GFS、MapReduce、BigTable)
从1.0向2.0的阶段最重要的改变是增加了YARN资源管理调度框架,它可以为不同的分析框架提供资源调度,把hadoop从一个框架转换成为了一个平台。
hadoop擅长日志分析,facebook就用Hive来进行日志分析。
HDFS
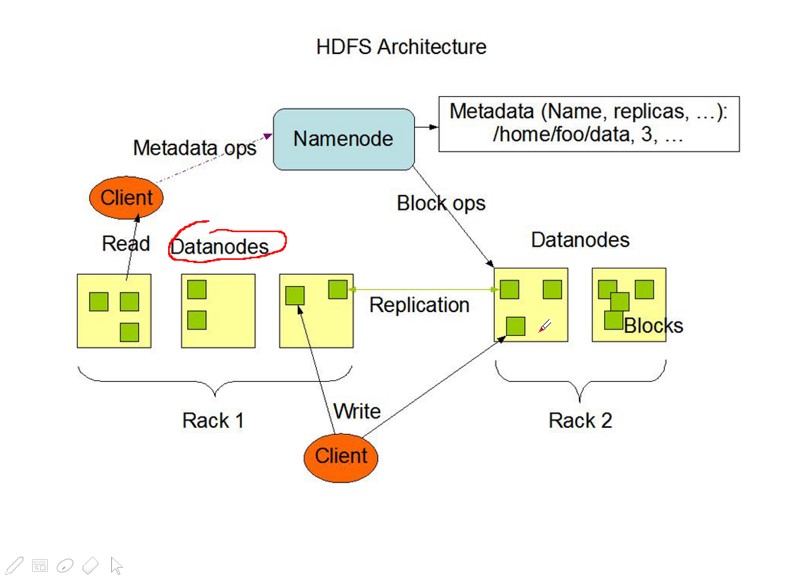
- DataNode 存储
NameNode 管理存储的数据
怎么解决海量数据的计算:
例如统计一个hdfs中有多少条数据,hadoop把这个过程分为两个阶段,一个是map阶段,就是统计每个dataNode中有多少条数据,然后是reduce阶段统计每个map计算出来的数据。可以把每个datanode节点放到一台机器上,这样就可以实现并发计算。
安装
现在新项目一般用2.2.0,比较稳定新。现在也有公司常用的是Cloudera自己封装的hadoop版本CDH,上面的API跟原生的API还是有点区别。还有一个HDP(Hortonworks Data Platform)比较流行的商业产品。
虚拟机配置
一般都部署在linux中,window也能用。
vmware搭建虚拟机的时候,会给虚拟机生成一个虚拟网关,然后虚拟机的网卡连接这个虚拟网关,同时给window产生一个虚拟的网卡也会链接这个虚拟网关,所以这个网关跟两个虚拟的网卡都必须在同一个网段。

- 配置ip地址可以直接用ui页面,也可以用setup命令。修改然后重新启动网络服务service network restart。
- 可以通过修改配置文件的方式:
/etc/sysconfig/network-script/ifcfg-eth0在后边。然后重启网络服务。- linux中让机器重启的时候不使用ui页面。可以修改/etc/inittab中的配置,把最后的级别改为3.
id: 3:initdefault - 让普通用户具有sudo执行权限,切换到root用户然后
vi /etc/sudoers加一行hadoop All=(ALL) ALL - 修改主机名/etc/sysconfig/network.
- 修改环境变量/etc/profile 让它生效:source /etc/profile
- 关闭防火墙:sudo iptables stop
- 查看防火墙状态:sudo iptables statu
- 查看防火墙的启动级别:sudo chkconfig iptables –list
- 关闭开机启动防火墙:sudo chkconfig iptables off
- linux中让机器重启的时候不使用ui页面。可以修改/etc/inittab中的配置,把最后的级别改为3.
- 可以通过修改配置文件的方式:
安装hadoop
- 上传解压
- lib 本地库 , include 也是本地库
hadoop中的jar包放在了share中的hadoop中,而doc则是放的文档没什么用
修改一些文件
hadoop-env.sh里面的环境变量JAVA_HOME- core-site在configuration中配置一些核心配置
|
|
配置hdfs-site.xml 参数,大多都有默认值,现在配置下面几个:也是跟上面的配置形式一样
- dfs.replication 副本数:一般配置3个,默认128
把mapred-site.xml.templent 去掉最后的后缀要不hadoop不会执行。
mapreduce.framework.name:yarn指定mapreduce程序用yarn来跑
yarn-site.xml中:
- yarn.resourcemanager.hostname:ip 配置yarn中的老大
- yarn.nodemanager.aux-services : mapreduce_shuffle 指定mapreduce程序里面map产生的结果怎么传递给reduce采用shuffle机制
slaves中,里面是启动datanode的地址
- 默认是localhost ,如果是多台集群,就要把所有的地址加在这里。
配置环境变量/etc/peofile
|
|
使用
- 启动时先格式化 : hadoop namenode -format 它会在规定hdfs存储的目录下新增几个文件
启动:sbin
- start-all.sh 启动所有进程
- start-dfs.sh 启动hdfs
- start-yarn.sh 启动yarn
推荐单独启动,能更好的体现出hadoop的性能。一般先启动hdfs再启动yarn,启动时会输密码。
- 可以通过ssh认证之后即不用输入密码。
0.0.0.0广播地址
- jps查看进程
- 内置了一个web服务:ip:50070
操作
- 上传一个文件:hadoop fs -put 文件名 hdfs://地址ip:9000
- 下载:hadoop fs -get hdfs://地址ip:9000/要下载的文件名
- 查看文件:
hadoop fs -ls hdfs上的路劲 显示结果:
hadooop fs -cat hdfs上的路劲运行一个小程序: /share/hadoop/mapreduce/ 这个文件夹里面的jar包
hadoop jar hadoop-mapreduce-example-2.4.1.jar pi 5 5- pi表示计算圆周率
- 第一个5表示map的任务数量
- 第二个5表示map的取样数,越多表示正确率越大
- 另外一个小程序计算whatcount,计算一个英文文档中每个单词出现的总次数
- 先新建一个文本,放入到级群里
hadoop fs -mkdir /workcount然后在创建hadoop fs -mkdir /workcount/input不能同时创建否则会报错,把文档上传hadoop fs -put test.txt /wordcount/input - 运行:
hadoop jar hadoop-mapreduce-example-2.4.1.jar wordcount /wordcount/input /wordcount/output
- 先新建一个文本,放入到级群里
实现机制
HDFS的实现思想:
- hdfs是通过分布式集群来存储文件,为客户端提供了一个便捷的访问方式,就是一个虚拟的目录
- 文件存储到hdfs集群中去的时候是被切分成block的
- 文件的block存放在若干台datanode节点上的,随机存储
- hdfs文件系统中的文件与真实的block之间有映射关系,由namenode管理
- 每一个blocek在集群中会存储多个副本,好处是可以提高数据的可靠性还可以提高访问的吞吐量
shell访问方式
- 查看帮助目录:hadoop fs
- hadoop fs -ls
- 第一个d是文件夹的意思,然后是可读可写可执行,然后有三组,一个是所属用户一个是所属组一个是其他人。
- 修改所属人的权限:
hadoop fs -chown 所属人:所属组 文件名称
- hadoop fs -cp 文件 文件夹:复制
- hadoop fs -df -h 目录:查看一个目录下有多少空间 -h 是便于阅读的意思
- 查看目录下的所有文件的大小
haddop fs -du -s -h hdfs://ip:9000/* - 删除:
hadoop fs -rm -r /aa/bb


