hdfs
NameNode工作机制
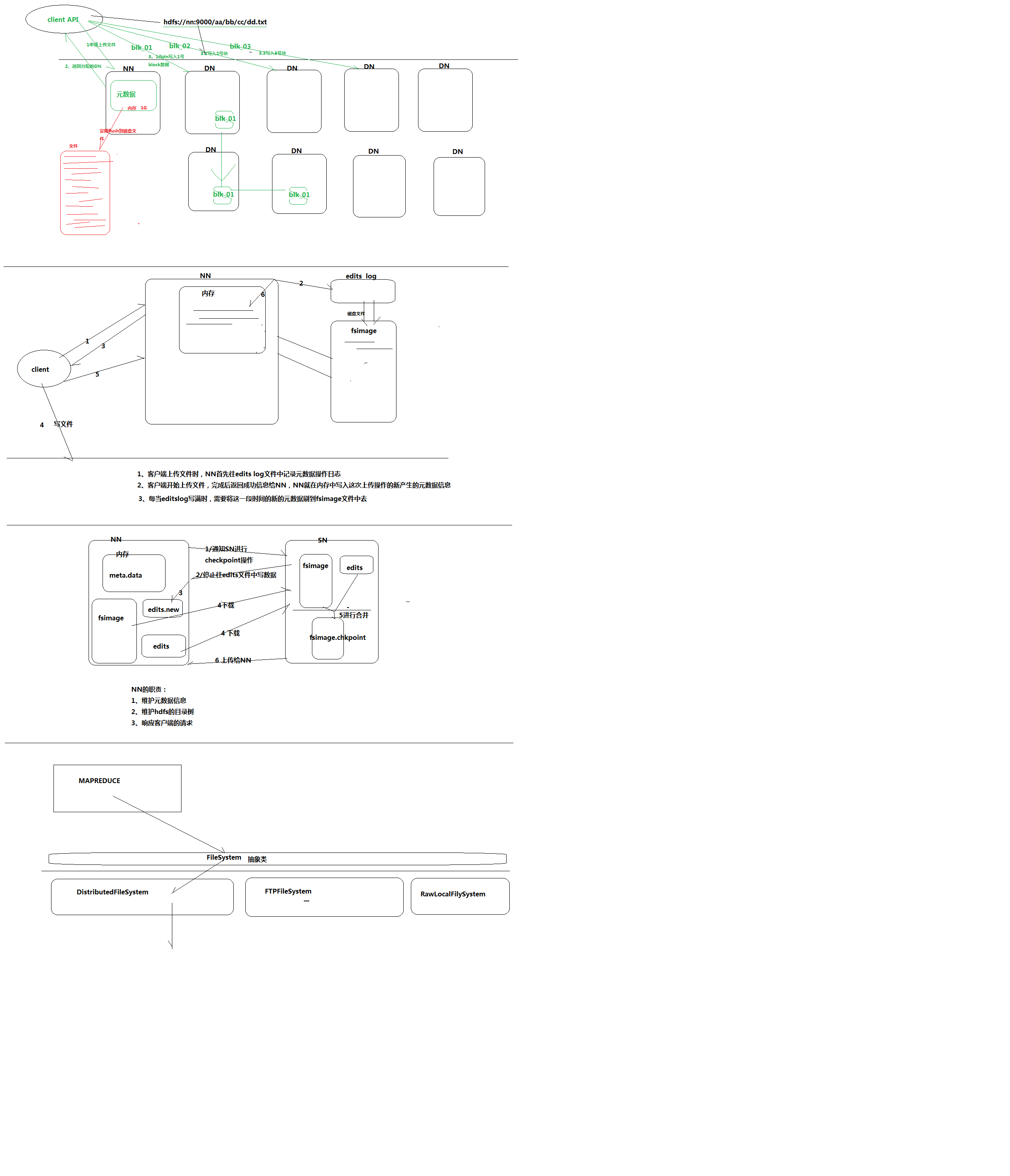
- hdfs写文件的过程,以及怎么保证元数据不丢失
- 首先向namenode申请上传文件,nameNode中的元数据返回要分配的DataNode有哪些
- 然后客户端会分别把要存的block写入datanode,只要要存的block存入成功就会返回成功信息
- datanode之间在形成管道,来写入block的副本,如果副本写入错误,datanode则会自动在别的datanode中重新写一次
- hdfs中有一个edits log日志文件来记录block存在哪些datanode中,当上传文件时nameNode首先往edits log文件中记录操作日志,当存入完成之后会把这些信息存入内存中。
- 每当editslog写满时,需要将这一段时间的新的元数据刷到fsimage也就是磁盘文件中去,这一步是由SecondaryNameNode来操作的
- 首先editlogs满了会通知secondaryNameNode进行checkpoint操作,然后namenode会停止往editlogs中写数据并切换到一个新的edit new,在后面会重新命名为edits。
- 然后secondaryNameNode会下载nameNode中的fsimage跟editlogs中的文件,进行合并生成一个新的fsimage.checkpoint文件
- 在把这个文件上传给NameNode替换掉以前的fsimage文件,一切重新开始。
什么时候checkpoint?
- fs.checkpoint.period 指定两次checkpoint的最大时间间隔,默认3600秒
- fs.checkpoint.size 规定edits文件的最大值,一旦超过这个值则强制checkpoint,不管是否达到最大时间间隔,默认大小是64M。
但是还有一个问题,在进行checkpoint时突然宕机了,再次重启虽然可以保证元数据的不丢失,但是在这个同时还会有应用在跟hdfs进行交互,这时怎么办。
- 可以有两个NameNode这是就要涉及到hdfs的高可用性的知识了,在后边再介绍
- 在写数据的时候其实有一个规则,在存的时候首先第一个block会存在namenode直接连的那个最近的datanode,它的副本会优先放在别的机架上,如果还有副本就会在本机架上在找一个datanode
- namenode中的文件存在了data — > name —->current 中
dataNode
提供真实文件数据的存储服务
- 文件块:最基本的存储单位。对于文件内容而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小,顺序对文件进行划分并编号,划分好的每一个块称一个Block。HDFS默认Block大小是128MB,以一个256MB文件,共有256/128=2个Block.(dfs.block.size)
不同于普通文件系统的是,HDFS中,如果一个文件小于一个数据块的大小,并不占用整个数据块存储空间。
存在datanode中的数据,可以直接找到他然后如果少于一个block并且是文件可以直接打开,如果分为了两个block可以把他们追加在一起,然后再解压还是能用的,追加
cat 文件1 >> 文件2
java操作hdfs
|
|
RPC远程过程调用
- 普通远程通信,tcp或soap
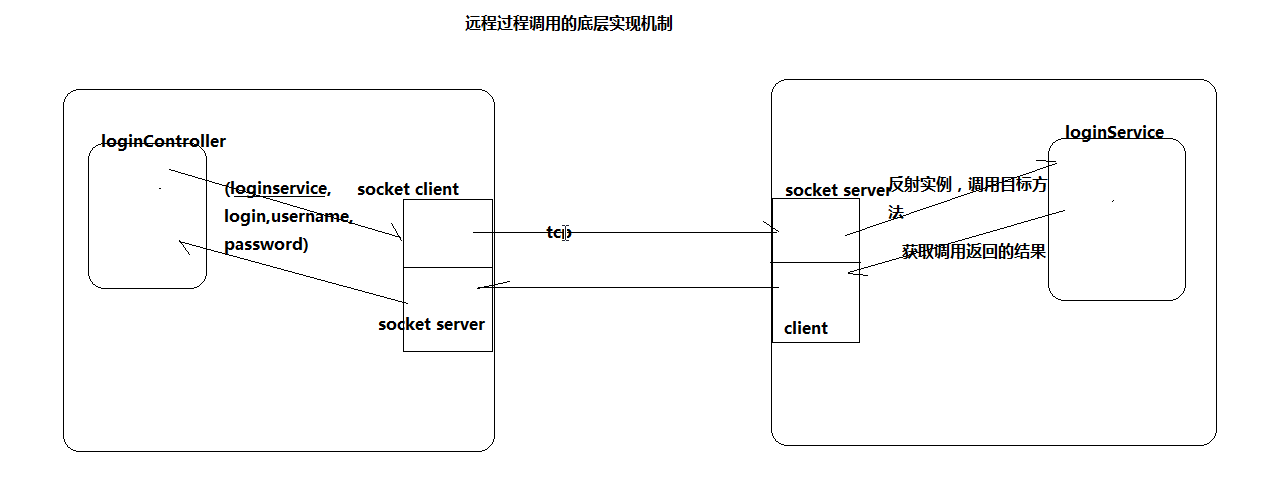
- hadoop自己封装的一个远程调用协议就是RPC,效率特别高
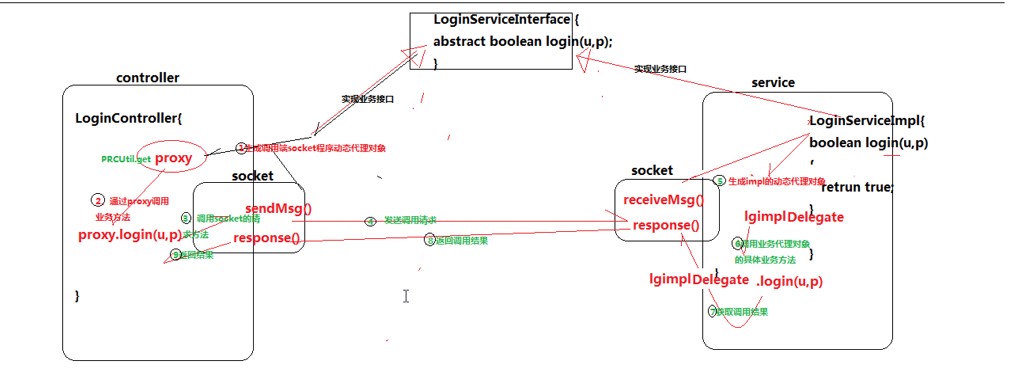
java实现
|
|


