map reduce
当面临海量数据处理的时候,需要把数据源文件放入分布式文件系统中,这时这个简单的处理就会变得很复杂,这时 map reduce 就发生了作用
所以我们程序员的工作就是写一些业务逻辑,这个逻辑本身不具备特别多分布式的特点,但是他要符合mapReduce的逻辑规范。
- map 局部处理
- reduce 汇总
编程的基本规范
一个简单的统计单词个数的map reduce程序:
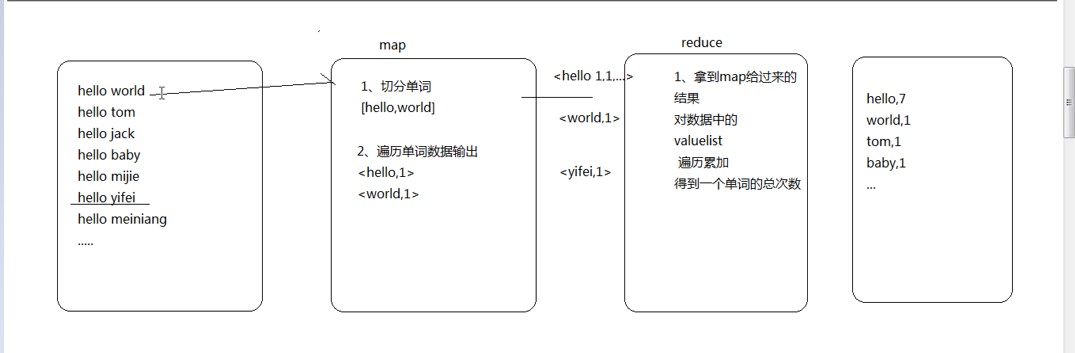
- LongWritable 其实就是Long类型只不过实现了hadoop自己的序列化封装
- Text就是hadoop实现了自己的序列化封装。
map:
reduce:
还需要一个类来描述整个的业务逻辑job描述类:
|
|
运行
- 上面的程序写好了之后可以打成一个jar包放在hadoop下运行
- 首先运行hadoop的集群包括yarn
- 然后在hadoop下创建输入目录和输出目录
hadoop fs -mkdir /wc hadoop fs -mkdir /wc/srcdata - 创建一个文件然后把文件上传到输入目录
hadoop fs -put words.log /wc/srcdata - 现在可以运行了
hadoop jar wc.jar com.test.mr.WCRunner
- 执行完了之后会在输出目录有两个文件,一个是空的表示执行成功了,另外一个是输出文件结果。
- 还可以运行在本地模式,在window下运行的话,可以把路径设置成本地路径
c:/wc/srcdata/,也可以是hafs路径hdfs://node1:9000/wc/srcdata/。- 这里有一个问题就是本地向hdfs中写数据的话可能没有权限,所以要改一下权限
hadoop fs -chmod -r 777 /wc
- 这里有一个问题就是本地向hdfs中写数据的话可能没有权限,所以要改一下权限
yarn任务调度
mapreduce和yarn的执行流程:
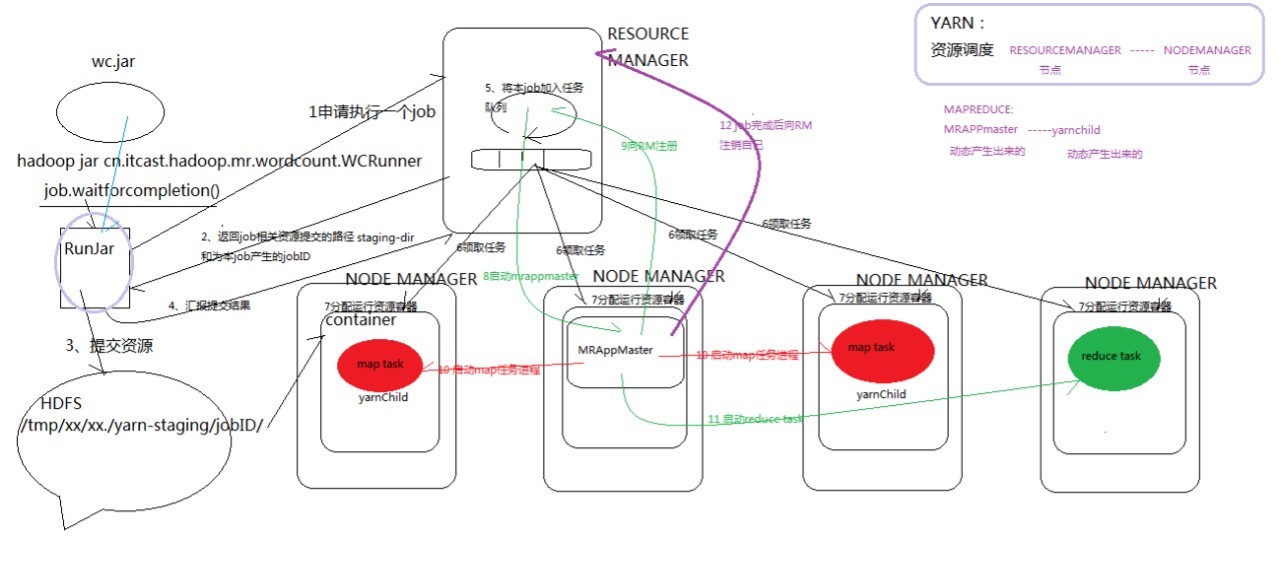
里面有很多的细节,也会有很多的进程,例如在运行上面写的程序时会产生一个Runjar,MRAppMaster,yarnChild..等进程可以通过jps查看
在本地运行的时候,是在本地jvm中运行,如果想用yarn来进行任务调度,可以把两个配置文件加进来
maper-site.xml yarn-site.xml- 还是会出现一个错误,因为任务调度找不到相应的jar包,所以可以在程序上面在加一个导入jar包
conf.set("mapreduce.job.jar","wc.jar");,然后把项目打成jar然后放在项目下边。 - 本地运行最好在linux中,因为window下的很多执行环境跟linux不一样,会报错
- 还是会出现一个错误,因为任务调度找不到相应的jar包,所以可以在程序上面在加一个导入jar包
hadoop的8088端口可以看到yarn的运行信息。
MR程序的几种提交运行模式
本地模型运行
- 在windows的eclipse里面直接运行main方法,就会将job提交给本地执行器localjobrunner执行
- 输入输出数据可以放在本地路径下
(c:/wc/srcdata/) - 输入输出数据也可以放在hdfs中
(hdfs://weekend110:9000/wc/srcdata)
- 输入输出数据可以放在本地路径下
- 在linux的eclipse里面直接运行main方法,但是不要添加yarn相关的配置,也会提交给localjobrunner执行
- 输入输出数据可以放在本地路径下
(/home/hadoop/wc/srcdata/) - 输入输出数据也可以放在hdfs中
(hdfs://weekend110:9000/wc/srcdata)
- 输入输出数据可以放在本地路径下
集群模式运行
- 将工程打成jar包,上传到服务器,然后用hadoop命令提交
hadoop jar wc.jar cn.itcast.hadoop.mr.wordcount.WCRunner - 在linux的eclipse中直接运行main方法,也可以提交到集群中去运行,但是,必须采取以下措施:
- 在工程src目录下加入
mapred-site.xml和yarn-site.xml - 将工程打成jar包
(wc.jar),同时在main方法中添加一个conf的配置参数conf.set("mapreduce.job.jar","wc.jar")
- 在工程src目录下加入
- 在windows的eclipse中直接运行main方法,也可以提交给集群中运行,但是因为平台不兼容,需要做很多的设置修改
- 要在windows中存放一份hadoop的安装包(解压好的)
- 要将其中的lib和bin目录替换成根据你的windows版本重新编译出的文件
- 再要配置系统环境变量 HADOOP_HOME 和 PATH
- 修改YarnRunner这个类的源码


