hadoop中的序列化机制
- 序列化:把对象转换为字节序列的过程
- 反序列化:把字节序列恢复为对象的过程
jdk自带的序列化会把要序列化的接口的所有继承类给序列化过去,hadoop则不会。
自定义统计
map
1234567891011121314151617181920212223/*** FlowBean 是我们自定义的一种数据类型,要在hadoop的各个节点之间传输,应该遵循hadoop的序列化机制* 就必须实现hadoop相应的序列化接口* @author duanhaitao@itcast.cn*/public class FlowSumMapper extends Mapper<LongWritable, Text, Text, FlowBean>{//拿到日志中的一行数据,切分各个字段,抽取出我们需要的字段:手机号,上行流量,下行流量,然后封装成kv发送出去protected void map(LongWritable key, Text value,Context context)throws IOException, InterruptedException {//拿一行数据String line = value.toString();//切分成各个字段String[] fields = StringUtils.split(line, "\t");//拿到我们需要的字段String phoneNB = fields[1];long u_flow = Long.parseLong(fields[7]);long d_flow = Long.parseLong(fields[8]);//封装数据为kv并输出context.write(new Text(phoneNB), new FlowBean(phoneNB,u_flow,d_flow));}}reduce
12345678910111213141516171819public class FlowSumReducer extends Reducer<Text, FlowBean, Text, FlowBean>{//框架每传递一组数据<1387788654,{flowbean,flowbean,flowbean,flowbean.....}>调用一次我们的reduce方法//reduce中的业务逻辑就是遍历values,然后进行累加求和再输出protected void reduce(Text key, Iterable<FlowBean> values,Context context)throws IOException, InterruptedException {long up_flow_counter = 0;long d_flow_counter = 0;for(FlowBean bean : values){up_flow_counter += bean.getUp_flow();d_flow_counter += bean.getD_flow();}context.write(key, new FlowBean(key.toString(), up_flow_counter, d_flow_counter));}}job
12345678910111213141516171819202122232425262728293031//这是job描述和提交类的规范写法public class FlowSumRunner extends Configured implements Tool{public int run(String[] args) throws Exception {Configuration conf = new Configuration();Job job = Job.getInstance(conf);job.setJarByClass(FlowSumRunner.class);job.setMapperClass(FlowSumMapper.class);job.setReducerClass(FlowSumReducer.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(FlowBean.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(FlowBean.class);FileInputFormat.setInputPaths(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));return job.waitForCompletion(true)?0:1;}public static void main(String[] args) throws Exception {int res = ToolRunner.run(new Configuration(), new FlowSumRunner(), args);System.exit(res);}}bean
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273747576777879808182public class FlowBean implements WritableComparable<FlowBean>{private String phoneNB;private long up_flow;private long d_flow;private long s_flow;//在反序列化时,反射机制需要调用空参构造函数,所以显示定义了一个空参构造函数public FlowBean(){}//为了对象数据的初始化方便,加入一个带参的构造函数public FlowBean(String phoneNB, long up_flow, long d_flow) {this.phoneNB = phoneNB;this.up_flow = up_flow;this.d_flow = d_flow;this.s_flow = up_flow + d_flow;}public String getPhoneNB() {return phoneNB;}public void setPhoneNB(String phoneNB) {this.phoneNB = phoneNB;}public long getUp_flow() {return up_flow;}public void setUp_flow(long up_flow) {this.up_flow = up_flow;}public long getD_flow() {return d_flow;}public void setD_flow(long d_flow) {this.d_flow = d_flow;}public long getS_flow() {return s_flow;}public void setS_flow(long s_flow) {this.s_flow = s_flow;}//将对象数据序列化到流中public void write(DataOutput out) throws IOException {out.writeUTF(phoneNB);out.writeLong(up_flow);out.writeLong(d_flow);out.writeLong(s_flow);}//从数据流中反序列出对象的数据//从数据流中读出对象字段时,必须跟序列化时的顺序保持一致public void readFields(DataInput in) throws IOException {phoneNB = in.readUTF();up_flow = in.readLong();d_flow = in.readLong();s_flow = in.readLong();}public String toString() {return "" + up_flow + "\t" +d_flow + "\t" + s_flow;}public int compareTo(FlowBean o) {return s_flow>o.getS_flow()?-1:1;}}
shuffle机制
map task的并发数是由切片的数量决定的,有多少切片,就启动多少map task
切片是一个逻辑的概念,指的就是文件中的数据的偏移量范围
切片的具体大小应该根据所处理的文件的大小来调整
hadoop 计算框架shuffle
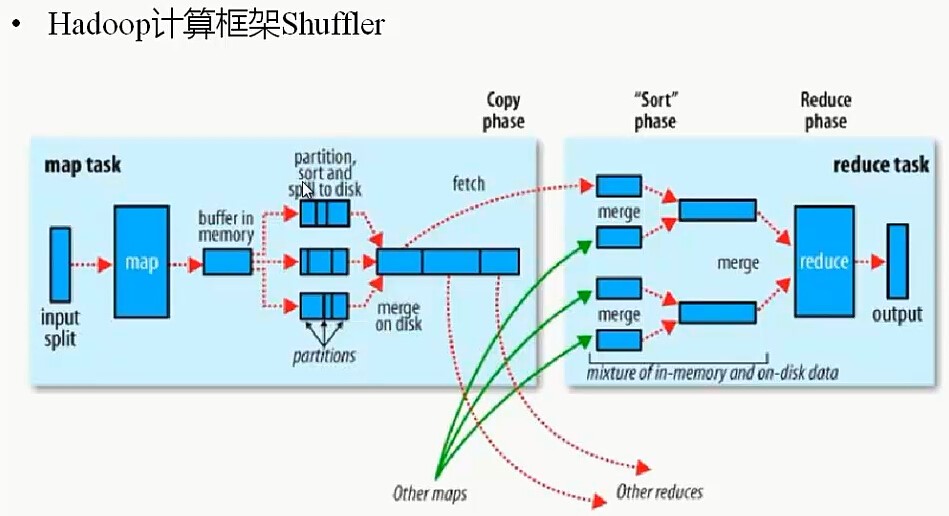
Shuffle过程,也称Copy阶段。reduce task从各个map task上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定的阀值,则写到磁盘上,否则直接放到内存中。
官方的Shuffle过程如上图所示,不过细节有错乱,官方图并没有说明partition、sort和combiner具体作用于哪个阶段。
注意:Shuffle过程是贯穿于map和reduce两个过程的!
Hadoop的集群环境,大部分的map task和reduce task是执行在不同的节点上的,那么reduce就要取map的输出结果。那么集群中运行多个Job时,task的正常执行会对集群内部的网络资源消耗严重。虽说这种消耗是正常的,是不可避免的,但是,我们可以采取措施尽可能的减少不必要的网络资源消耗。另一方面,每个节点的内部,相比于内存,磁盘IO对Job完成时间的影响相当的大。
所以:从以上分析,shuffle过程的基本要求:
1.完整地从map task端拉取数据到reduce task端
2.在拉取数据的过程中,尽可能地减少网络资源的消耗
3.尽可能地减少磁盘IO对task执行效率的影响那么,Shuffle的设计目的就要满足以下条件:
1.保证拉取数据的完整性
2.尽可能地减少拉取数据的数据量
3.尽可能地使用节点的内存而不是磁盘


