zookeeper
zookeeper 是Goole的Chubby的一个开源的项目的实现,是Hadoop的分布式协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等。
- 作用:
- 提供对数据节点的监听器
- 提供少量数据的存储和管理
- zookeeper也有角色:Follower和Leader
- Leader主要负责写操作
- 还有一种是观察者:observer,不参与投票
安装
下载安装后打开目录
更改conf下的
zoo_sample.cfg为zoo.cfg.- 此配置文件里面有端口号,存储的信息位置(不建议用默认的额tmp),超时时间等配置项
- 还要自己加一个zookeeper集群有哪些机器,加在最后边。1234server.1=node1: 2888:3888server.2=node2: 2888:3888server.3=node3: 2888:3888//其中的1 2 3 是可以为其他数字的需要在选定的机器上配置一下,需要在存储信息的位置下建一个新的文件myid里面写上配置的数字。例如在本台机器上就要写echo 1 > myid
启动
bin/zkserver.sh start- 如果是集群的话,他没有一个启动所有集群的脚本需要一个一个启动,也可以自己写一个
- 可以启动自带的客户端连接到命令行中去
zkCli.sh,在这里就可以写数据了
要想保证zookeeper存活,至少应该有大于一半的机器是正常的

hdfs高可用 HA
前面讲到的hdfs的架构,namenode和datanode服务的可靠性有了,但是可用性不高
自己实现高可用使用qjournal框架

。。。。。
Hive
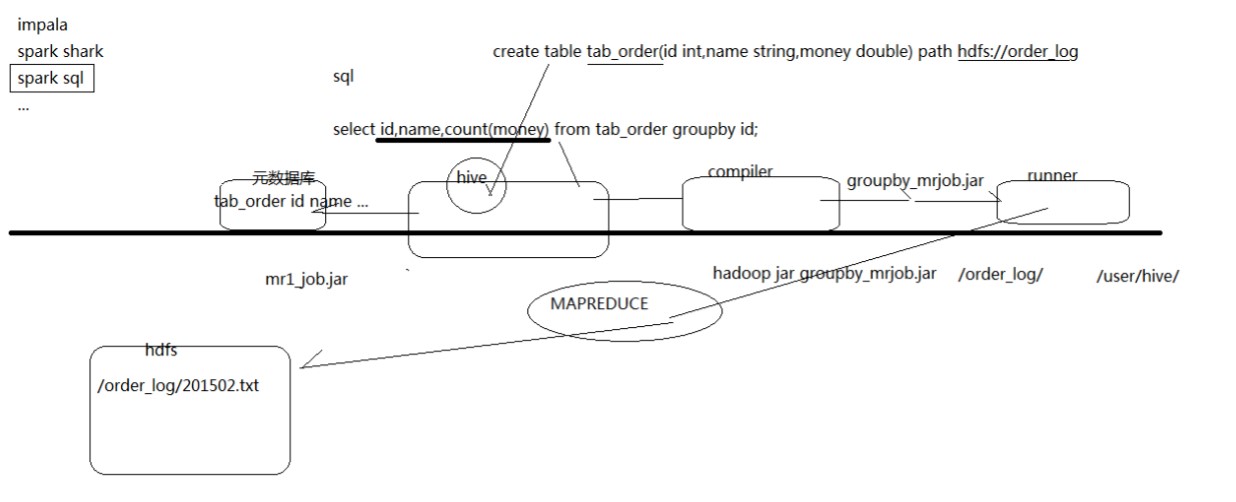
Hive 是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 QL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
- 是一个工具,不是服务器
- 把sql语句给hive然后翻译成mr认识的语句去操作大数据量处理
- hive不支持一条一条数据测插入的,只支持已经存在的数据的查询。使用select语句即可

安装使用
安装好了直接去bin底下运行hive即可,有一个问题就是运行的时候是在bin下运行的就会在这个目录下生成一个以db结尾的文件,创建的表就在这个文件中,但是如果下次启动的时候不是从这个bin目录下启动的话就会在其他的目录下再次生成一个这样的文件,每个人创建的表就不能通用了,所以需要配置一个mysql用来管理元数据这样就能通用了。
进入conf目录下然后把
hive-default.xml.template改为hive-default.xml,然后打开配置,只留下边的即可123456789101112131415161718<configuration><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc : mysql://weekend01:3306/hive?createDatabaseIfNotExist=true</value></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><property><name>javax.jdo.option.ConnectionPassword</name><value>root</value></property></configuration>还需要加一个mysql的驱动jar包:
mysql-connector-java-5.1.28.jar
hive hql语句:见附件
- 建表之后可以在数据库中查看会生成很多mysql的表这里边存的就是hive的表信息,它的具体信息会存在hdfs中
hive如果在默认的库下建表则会在hdfs中的hive指定目录下生成一个文件,如果在hive中建一个库之后再建表,则会在hive中的目录下在生成一个库的名字为命名的文件夹,再在地下生成一个表名的文件
hive可以上传本地或者是hdfs的文件到它的表中,只要格式正确就行,如果在hdfs中上传到hive的话,会剪切那个文件到hive指定的表文件中
如果上传的文件格式与定义的hive表不一致时,如果多出字段则,去掉多余的字段,如果少的话会填充null而且null总会是一条记录中的最后一个
hive有一个表叫做
external table这样的表就是如果它里面的信息在hdfs上的话,也不会剪切这个文件到指定的目录,这样就可以避免一些麻烦。这个表的建表语句就是多了一个external123456CREATE EXTERNAL TABLE tab_ip_ext(id int, name string,ip STRING,country STRING)ROW FORMAT DELIMITED FIELDS TERMINATED BY ','STORED AS TEXTFILELOCATION '/external/hive';


