介绍
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
四种运行模式:local(多用于测试),standalone,Mesos,YARN
一切都以RDD为基础(Resilient Distributed Dataset):弹性的分布式数据集
- 一列分片
- 每一个分片上都会有函数
- 一系列的依赖
- 对key-value的RDD可以指定一个分片器
- 指定运算在哪台机器上
容错:每个RDD都会记录自己依赖于哪个RDD,万一某个RDD的某些partition挂了,可以通过其它RDD并行计算迅速恢复出来。
集群配置:
1234567891011121314spark_env.shexport JAVA_HOME=export SPARK_MASTER_IP=export SPARK_WORKER_CORES=export SPARK_WORKER_INSTANCES =export SPARK_WORKER_MEMORY=export SPARK_MASTER_PORT=export SPARK_JAVA_OPTS="-verbose:gc -XX:-PrintGCDetails -XX:+PrintGCTimeStamps"salvesxx.xx.xx.2xx.xx.xx.3xx.xx.xx.4xx.xx.xx.5配置好之后启动的时候,用
MASTER=spark://host:port ./spark-shell因为在0.9.0之前有一些错误,所以需要指定master要不然可能会是standalone模式启动。可以指定启动时候的内存,可以直接在启动脚本上设置
export SPARK_MEM=25g在集群上运行spark的jar包
java -jar 运行的jar 依赖的jar 要取出来的数据位置 放到的位置
RDDs
弹性分布式数据集(RDDs)。 Spark 核心的概念是 Resilient Distributed Dataset (RDD):一个可并行操作的有容错机制的数据集合。有 2 种方式创建 RDDs:第一种是在你的驱动程序中并行化一个已经存在的集合;另外一种是引用一个外部存储系统的数据集,例如共享的文件系统,HDFS,HBase或其他 Hadoop 数据格式的数据源。
并行集合
- 并行集合 (Parallelized collections) 的创建是通过在一个已有的集合(Scala Seq)上调用 SparkContext 的 parallelize 方法实现的。集合中的元素被复制到一个可并行操作的分布式数据集中。例如,这里演示了如何在一个包含 1 到 5 的数组中创建并行集合:
|
|
一旦创建完成,这个分布式数据集
(distData)就可以被并行操作。例如,我们可以调用distData.reduce((a, b) => a + b)将这个数组中的元素相加。我们以后再描述在分布式上的一些操作。并行集合一个很重要的参数是切片数
(slices),表示一个数据集切分的份数。Spark 会在集群上为每一个切片运行一个任务。你可以在集群上为每个 CPU 设置 2-4 个切片(slices)。正常情况下,Spark 会试着基于你的集群状况自动地设置切片的数目。然而,你也可以通过parallelize的第二个参数手动地设置(例如:sc.parallelize(data, 10))。
外部数据集
Spark 可以从任何一个 Hadoop 支持的存储源创建分布式数据集,包括你的本地文件系统,HDFS,Cassandra,HBase,Amazon S3等。 Spark 支持文本文件(text files),SequenceFiles 和其他 Hadoop InputFormat。
- 文本文件 RDDs 可以使用 SparkContext 的 textFile 方法创建。 在这个方法里传入文件的 URI (机器上的本地路径或 hdfs://,s3n:// 等),然后它会将文件读取成一个行集合。这里是一个调用例子:
|
|
一旦创建完成,distFiile 就能做数据集操作。例如,我们可以用下面的方式使用 map 和 reduce 操作将所有行的长度相加:distFile.map(s => s.length).reduce((a, b) => a + b)。
注意,Spark 读文件时:
如果使用本地文件系统路径,文件必须能在 work 节点上用相同的路径访问到。要么复制文件到所有的 workers,要么使用网络的方式共享文件系统。
所有 Spark 的基于文件的方法,包括 textFile,能很好地支持文件目录,压缩过的文件和通配符。例如,你可以使用 textFile(“/my/文件目录”),textFile(“/my/文件目录/.txt”) 和 textFile(“/my/文件目录/.gz”)。
textFile 方法也可以选择第二个可选参数来控制切片(slices)的数目。默认情况下,Spark 为每一个文件块(HDFS 默认文件块大小是 64M)创建一个切片(slice)。但是你也可以通过一个更大的值来设置一个更高的切片数目。注意,你不能设置一个小于文件块数目的切片值。
除了文本文件,Spark 的 Scala API 支持其他几种数据格式:
SparkContext.wholeTextFiles 让你读取一个包含多个小文本文件的文件目录并且返回每一个(filename, content)对。与 textFile 的差异是:它记录的是每个文件中的每一行。
对于 SequenceFiles,可以使用 SparkContext 的 sequenceFile[K, V] 方法创建,K 和 V 分别对应的是 key 和 values 的类型。像 IntWritable 与 Text 一样,它们必须是 Hadoop 的 Writable 接口的子类。另外,对于几种通用的 Writables,Spark 允许你指定原生类型来替代。例如: sequenceFile[Int, String] 将会自动读取 IntWritables 和 Text。
对于其他的 Hadoop InputFormats,你可以使用 SparkContext.hadoopRDD 方法,它可以指定任意的 JobConf,输入格式(InputFormat),key 类型,values 类型。你可以跟设置 Hadoop job 一样的方法设置输入源。你还可以在新的 MapReduce 接口(org.apache.hadoop.mapreduce)基础上使用 SparkContext.newAPIHadoopRDD(译者注:老的接口是 SparkContext.newHadoopRDD)。
RDD.saveAsObjectFile 和 SparkContext.objectFile 支持保存一个RDD,保存格式是一个简单的 Java 对象序列化格式。这是一种效率不高的专有格式,如 Avro,它提供了简单的方法来保存任何一个 RDD。
RDD操作
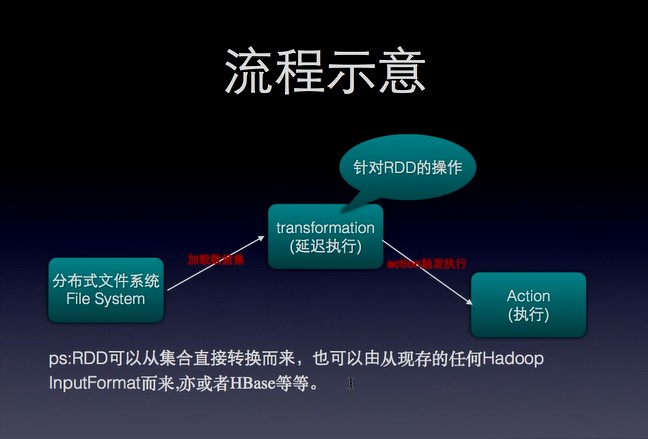
RDDs 支持 2 种类型的操作:转换(transformations) 从已经存在的数据集中创建一个新的数据集;动作(actions) 在数据集上进行计算之后返回一个值到驱动程序。例如,map 是一个转换操作,它将每一个数据集元素传递给一个函数并且返回一个新的 RDD。另一方面,reduce 是一个动作,它使用相同的函数来聚合 RDD 的所有元素,并且将最终的结果返回到驱动程序(不过也有一个并行 reduceByKey 能返回一个分布式数据集)。
在 Spark 中,所有的转换(transformations)都是惰性(lazy)的,它们不会马上计算它们的结果。相反的,它们仅仅记录转换操作是应用到哪些基础数据集(例如一个文件)上的。转换仅仅在这个时候计算:当动作(action) 需要一个结果返回给驱动程序的时候。这个设计能够让 Spark 运行得更加高效。例如,我们可以实现:通过 map 创建一个新数据集在 reduce 中使用,并且仅仅返回 reduce 的结果给 driver,而不是整个大的映射过的数据集。
默认情况下,每一个转换过的 RDD 会在每次执行动作(action)的时候重新计算一次。然而,你也可以使用 persist (或 cache)方法持久化(persist)一个 RDD 到内存中。在这个情况下,Spark 会在集群上保存相关的元素,在你下次查询的时候会变得更快。在这里也同样支持持久化 RDD 到磁盘,或在多个节点间复制。
为了说明 RDD 基本知识,考虑下面的简单程序:
123val lines = sc.textFile("data.txt")val lineLengths = lines.map(s => s.length)val totalLength = lineLengths.reduce((a, b) => a + b)第一行是定义来自于外部文件的 RDD。这个数据集并没有加载到内存或做其他的操作:lines 仅仅是一个指向文件的指针。第二行是定义 lineLengths,它是 map 转换(transformation)的结果。同样,lineLengths 由于懒惰模式也没有立即计算。最后,我们执行 reduce,它是一个动作(action)。在这个地方,Spark 把计算分成多个任务(task),并且让它们运行在多个机器上。每台机器都运行自己的 map 部分和本地 reduce 部分。然后仅仅将结果返回给驱动程序。
如果我们想要再次使用 lineLengths,我们可以添加:
lineLengths.persist(),在 reduce 之前,它会导致 lineLengths 在第一次计算完成之后保存到内存中。
使用键值对
虽然很多 Spark 操作工作在包含任意类型对象的 RDDs 上的,但是少数几个特殊操作仅仅在键值(key-value)对 RDDs 上可用。最常见的是分布式 “shuffle” 操作,例如根据一个 key 对一组数据进行分组和聚合。
在 Scala 中,这些操作在包含二元组(Tuple2)(在语言的内建元组中,通过简单的写 (a, b) 创建) 的 RDD 上自动地变成可用的,只要在你的程序中导入 org.apache.spark.SparkContext._ 来启用 Spark 的隐式转换。在 PairRDDFunctions 的类里键值对操作是可以使用的,如果你导入隐式转换它会自动地包装成元组 RDD。
例如,下面的代码在键值对上使用 reduceByKey 操作来统计在一个文件里每一行文本内容出现的次数:
|
|
我们也可以使用 counts.sortByKey(),例如,将键值对按照字母进行排序,最后 counts.collect() 把它们作为一个对象数组带回到驱动程序。
注意:当使用一个自定义对象作为 key 在使用键值对操作的时候,你需要确保自定义 equals() 方法和 hashCode() 方法是匹配的。
Transformations
下面的表格列了 Spark 支持的一些常用 transformations。
| Transformation | Meaning |
|---|---|
| map(func) | 返回一个新的分布式数据集,将数据源的每一个元素传递给函数func映射组成。 |
| filter(func) | 返回一个新的数据集,从数据源中选中一些元素通过函数 func 返回true。 |
| flatMap(func) | 类似于 map,但是每个输入项能被映射成多个输出项(所以 func必须返回一个 Seq,而不是单个 item)。 |
| mapPartitions(func) | 类似于 map,但是分别运行在 RDD 的每个分区上,所以 func的类型必须是 Iterator |
| mapPartitionsWithIndex(func) | 类似于 mapPartitions,但是 func 需要提供一个 integer 值描述索引(index),所以 func 的类型必须是 (Int, Iterator) => Iterator当运行在类型为 T 的 RDD 上。 |
| sample(withReplacement, fraction, seed) | 对数据进行采样。 |
| union(otherDataset) | 返回一个包含源数据集和参数中元素的并集的新数据集。 |
| intersection(otherDataset) | 返回包含源数据集和参数中的元素的新RDD。 |
| distinct([numTasks])) | 返回一个包含源数据集的不同元素的新数据集。 |
| groupByKey([numTasks]) | 当对(K,V)对的数据集进行调用时,返回(K,Iterable)的数据集。注意:如果要分组以便在每个键上执行聚合(例如总和或平均值),则使用reduceByKey或combineByKey将产生更好的性能。注意:默认情况下,输出中的并行级别取决于父RDD的分区数。您可以传递一个可选的numTasks参数来设置不同数量的任务。 |
| reduceByKey(func, [numTasks]) | 当对(K,V)对的数据集进行调用时,返回(K,V对的数据集,其中使用给定的reduce函数func聚合每个键的值,该函数必须是类型(V,V)=> V.像groupByKey一样,可以通过可选的第二个参数来配置reduce任务的数量。 |
| aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) | 当(K,V)对的数据集被调用时,返回一个数据集(K,U)对,其中使用给定的组合函数和中性的“零”值对每个键的值进行聚合。允许不同于输入值类型的聚合值类型,同时避免不必要的分配。像groupByKey一样,reduce任务的数量可以通过可选的第二个参数进行配置。 |
| sortByKey([ascending], [numTasks]) | 在K实现有序的(K,V)对的数据集上被调用时,按照布尔升序参数中指定的按升序或降序的顺序返回按键排序的(K,V)对的数据集。 |
| join(otherDataset, [numTasks]) | 当对类型(K,V)和(K,W)的数据集进行调用时,返回一个(K,(V,W))对的数据集与每个键的所有元素对。还通过leftOuterJoin和rightOuterJoin支持外连接。 |
| cogroup(otherDataset, [numTasks]) | 当调用类型(K,V)和(K,W)的数据集时,返回一个数据集(K,Iterable,Iterable元组。这个操作也叫做GroupWith。 |
| cartesian(otherDataset) | 当对类型T和U的数据集进行调用时,返回(T,U)对(所有元素对)的数据集。 |
| pipe(command, [envVars]) | 通过shell命令管理RDD的每个分区,例如一个Perl或bash脚本。RDD元素被写入到进程的stdin中,并且将其输出的行输出返回为字符串的RDD。 |
| coalesce(numPartitions) | 将RDD中的分区数减少到numPartition。过滤大型数据集后,对于运行操作更有效。 |
| repartition(numPartitions) | 随机重新清理RDD中的数据以创建更多或更少的分区,并在其间平衡。这总是通过网络洗牌所有的数据。 |
Actions
下面的表格列了 Spark 支持的一些常用 actions。
| Action | Meaning |
|---|---|
| reduce(func) | Aggregate the elements of the dataset using a function func (which takes two arguments and returns one). The function should be commutative and associative so that it can be computed correctly in parallel. |
| collect() | Return all the elements of the dataset as an array at the driver program. This is usually useful after a filter or other operation that returns a sufficiently small subset of the data. |
| count() | Return the number of elements in the dataset. |
| first() | Return the first element of the dataset (similar to take(1)). |
| take(n) | Return an array with the first n elements of the dataset. Note that this is currently not executed in parallel. Instead, the driver program computes all the elements. |
| takeSample(withReplacement, num, [seed]) | Return an array with a random sample of num elements of the dataset, with or without replacement, optionally pre-specifying a random number generator seed. |
| takeOrdered(n, [ordering]) | Return the first n elements of the RDD using either their natural order or a custom comparator. |
| saveAsTextFile(path) | Write the elements of the dataset as a text file (or set of text files) in a given directory in the local filesystem, HDFS or any other Hadoop-supported file system. Spark will call toString on each element to convert it to a line of text in the file. |
| saveAsSequenceFile(path) (Java and Scala) | Write the elements of the dataset as a Hadoop SequenceFile in a given path in the local filesystem, HDFS or any other Hadoop-supported file system. This is available on RDDs of key-value pairs that either implement Hadoop’s Writable interface. In Scala, it is also available on types that are implicitly convertible to Writable (Spark includes conversions for basic types like Int, Double, String, etc). |
| saveAsObjectFile(path) (Java and Scala) | Write the elements of the dataset in a simple format using Java serialization, which can then be loaded using SparkContext.objectFile(). |
| countByKey() | Only available on RDDs of type (K, V). Returns a hashmap of (K, Int) pairs with the count of each key. |
| foreach(func) | Run a function func on each element of the dataset. This is usually done for side effects such as updating an accumulator variable (see below) or interacting with external storage systems. |
SparkStreaming
SparkStreaming 是一个流式处理框架,处理的模式是微批处理(微批有多大?通过时间来设置这个批有多大[For example :batch Interval 5s])
SparkStreaming 基于DStream(Discretized Streams:离散的数据流)来进行编程,处理的是一个流,这个流什么时候切成一个rdd–>根据batchinterval 来决定何时切割成一个RDD。


