介绍
- 一个开源的分布式实时计算系统,可以简单、可靠的处理大量的数据流。被称作”实时的hadoop”.
- 主要用在流式的数据处理,例如数据一边进来一边转换格式。hadoop是批量离线处理,storm是实时的。
- 使用场景:实时分析、在线机器学习,持续计算,分布式RPC,ETL等等

- storm的典型拓扑图
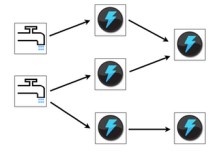
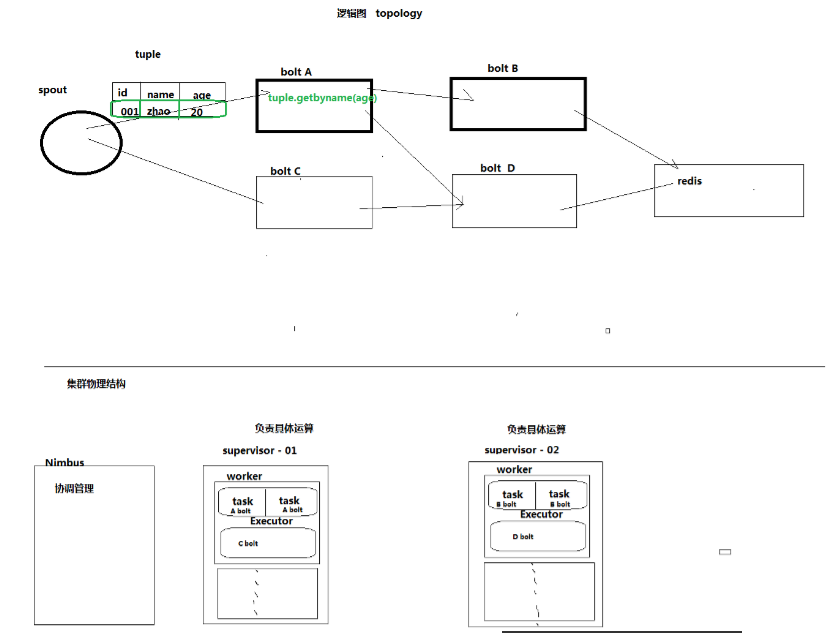
- 逻辑结构跟物理结构
安装
- 安装一个zookeeper集群
- 上传storm的安装包,解压
- 修改配置文件storm.yaml,下面是必须填充的1234567#所使用的zookeeper集群主机storm.zookeeper.servers:- "weekend05"- "weekend06"- "weekend07"#nimbus所在的主机名,协调节点或者是说主节点nimbus.host: "weekend05"
- 启动storm
- 在nimbus主机上,启动nimbus
nohup ./storm nimbus,启动提供web访问的进程nohup ./storm ui - 在supervisor主机上
nohup ./storm supervisor
- 在nimbus主机上,启动nimbus
java小demo
随机读单词装换成大写然后再加上时间
模拟spouts数据的输入
|
|
- bolts转换成大写
|
|
- 添加时间后缀
|
|
- 管理类
|
|


